Unveiling the Power of Self-Organizing Maps in Python: A Comprehensive Exploration
Related Articles: Unveiling the Power of Self-Organizing Maps in Python: A Comprehensive Exploration
Introduction
In this auspicious occasion, we are delighted to delve into the intriguing topic related to Unveiling the Power of Self-Organizing Maps in Python: A Comprehensive Exploration. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Unveiling the Power of Self-Organizing Maps in Python: A Comprehensive Exploration

The realm of machine learning encompasses a diverse array of techniques, each tailored to address specific challenges. Among these, the Self-Organizing Map (SOM), also known as a Kohonen map, stands out as a powerful unsupervised learning algorithm with unique capabilities. This article delves into the intricacies of SOMs, focusing on their implementation in Python, highlighting their importance and benefits in data analysis and visualization.
Understanding the Essence of Self-Organizing Maps
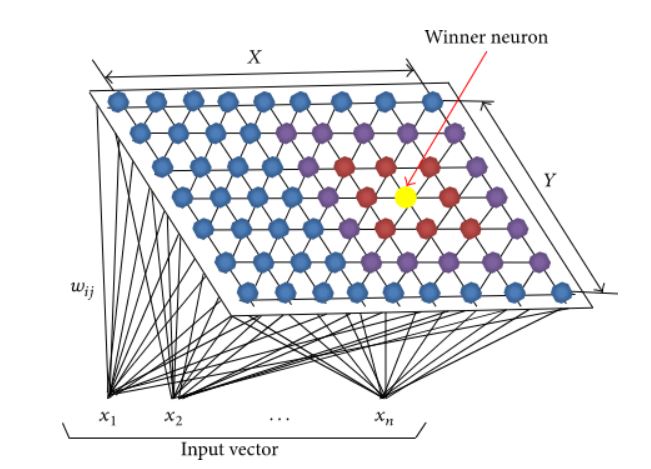
At its core, a SOM is a neural network designed to map high-dimensional data onto a low-dimensional space, typically a two-dimensional grid. This process, known as dimensionality reduction, allows for the visualization and exploration of complex datasets in a more intuitive manner. The map’s structure is characterized by a collection of neurons, each representing a specific region of the input data space.
The training process of a SOM involves iteratively adjusting the weights associated with each neuron, aiming to create a topological representation of the input data. This means that neurons representing similar data points are positioned closer together on the map, while neurons representing dissimilar data points are placed farther apart. The resulting map effectively captures the underlying structure and relationships within the data, revealing patterns and clusters that might otherwise remain hidden.
Python Implementation: A Practical Perspective
Python, with its extensive libraries and user-friendly syntax, provides a conducive environment for implementing and exploring SOMs. The minisom library, specifically designed for SOMs, offers a straightforward and efficient approach. Let’s illustrate this with a simple example:
from minisom import MiniSom
# Sample data
data = [[1, 2], [1.5, 1.8], [5, 8], [8, 8], [1, 0.6], [9, 11]]
# Initialize the SOM with a 5x5 grid and a learning rate of 0.5
som = MiniSom(5, 5, 2, sigma=0.3, learning_rate=0.5)
# Train the SOM
som.train_batch(data, 100)
# Visualize the map
som.plot_response(data)This code snippet demonstrates the basic steps involved in training and visualizing a SOM. The MiniSom class provides functions for initializing, training, and visualizing the map. The train_batch method trains the SOM using the provided data, while the plot_response method generates a visual representation of the map, highlighting the distribution of data points across the grid.
Benefits and Applications of Self-Organizing Maps
The versatility of SOMs makes them invaluable in a wide range of applications, including:
-
Data Visualization and Exploration: SOMs excel at revealing hidden patterns and clusters within complex datasets, providing insights into the underlying structure and relationships. This capability is particularly useful for exploratory data analysis, aiding in the identification of key features and potential anomalies.
-
Feature Extraction and Dimensionality Reduction: By mapping high-dimensional data onto a lower-dimensional space, SOMs effectively perform feature extraction and dimensionality reduction. This process can simplify subsequent analysis and improve the performance of other machine learning models.
-
Clustering and Classification: The topological organization of neurons in a SOM facilitates clustering and classification tasks. Data points that map to the same neuron are considered to belong to the same cluster, while the proximity of neurons can be used to classify new data points.
-
Anomaly Detection: SOMs can be utilized for detecting outliers or anomalous data points. These are typically represented by neurons that are sparsely populated or located at the periphery of the map.
-
Data Compression: SOMs can be used for data compression, reducing the storage space required for large datasets while preserving essential information.
Addressing Common Queries
1. How does the SOM training process work?
The training process involves iteratively adjusting the weights associated with each neuron based on the input data. This adjustment is guided by the concept of "neighborhood," where neurons close to the best-matching unit (BMU) are also updated, albeit with a smaller weight change. The learning rate and the neighborhood radius gradually decrease over time, ensuring that the map converges to a stable state.
2. What are the key parameters to consider when building a SOM?
The size of the map (number of neurons), the learning rate, and the neighborhood radius are crucial parameters that influence the performance of the SOM. These parameters should be carefully selected based on the characteristics of the data and the desired outcome.
3. How can I evaluate the performance of a SOM?
Several metrics can be used to assess the performance of a SOM, including:
- Quantization Error: Measures the average distance between data points and their corresponding BMUs.
- Topographic Error: Evaluates how well the SOM preserves the topological relationships in the data.
- Silhouette Score: Measures the similarity of data points within a cluster compared to other clusters.
4. What are some potential limitations of SOMs?
While powerful, SOMs do have limitations:
- Sensitivity to Initialization: The initial placement of neurons can influence the final structure of the map.
- Difficulty in Handling High-Dimensional Data: SOMs can become computationally expensive and less effective when dealing with very high-dimensional data.
- Lack of Interpretability: The resulting map may not always be easily interpretable, requiring careful analysis and visualization techniques.
Tips for Effective SOM Implementation
- Data Preprocessing: Ensure that the data is normalized or standardized before training the SOM to prevent bias due to differing scales.
- Experiment with Parameters: Adjust the learning rate, neighborhood radius, and map size to optimize the performance of the SOM.
- Visualize and Interpret: Utilize visualization techniques to understand the structure and patterns revealed by the SOM.
- Consider Alternative Techniques: In cases where SOMs are not suitable, explore other dimensionality reduction techniques such as Principal Component Analysis (PCA) or t-Distributed Stochastic Neighbor Embedding (t-SNE).
Conclusion
Self-Organizing Maps offer a powerful and versatile approach to data analysis and visualization. Their ability to map high-dimensional data onto a low-dimensional space, reveal hidden patterns, and facilitate clustering and classification makes them valuable tools in various domains. By leveraging the capabilities of Python libraries like minisom, researchers and practitioners can effectively harness the power of SOMs to gain deeper insights from their data. While SOMs have limitations, careful selection of parameters, appropriate data preprocessing, and visualization techniques can mitigate these challenges and unlock the full potential of this valuable machine learning algorithm.






Closure
Thus, we hope this article has provided valuable insights into Unveiling the Power of Self-Organizing Maps in Python: A Comprehensive Exploration. We thank you for taking the time to read this article. See you in our next article!