Unveiling the Power of MapReduce in Python: A Comprehensive Guide
Related Articles: Unveiling the Power of MapReduce in Python: A Comprehensive Guide
Introduction
In this auspicious occasion, we are delighted to delve into the intriguing topic related to Unveiling the Power of MapReduce in Python: A Comprehensive Guide. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Unveiling the Power of MapReduce in Python: A Comprehensive Guide
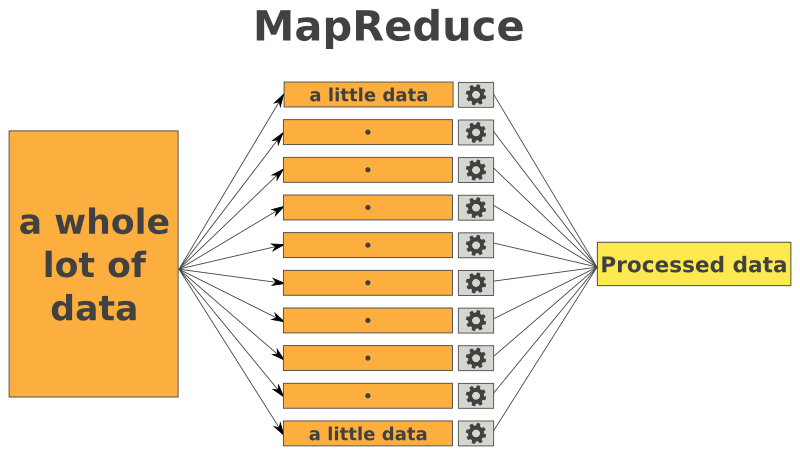
The MapReduce programming model, a paradigm for processing large datasets, has revolutionized data analysis by offering a simple yet powerful approach to parallelize computations. This model, often implemented in Python, empowers developers to tackle complex data challenges with ease and efficiency. This article delves into the core concepts of MapReduce, explores practical Python examples, and highlights its benefits in various scenarios.
Understanding the MapReduce Paradigm
At its heart, MapReduce operates on two fundamental functions:
- Map: This function takes each data element as input and transforms it into key-value pairs. The map phase essentially dissects the data, extracting relevant information and assigning it to specific keys.
- Reduce: This function aggregates the values associated with the same key produced by the map phase. The reduce phase consolidates the information, performing calculations or operations on grouped values.
Illustrative Examples: MapReduce in Action
To solidify the understanding of MapReduce, let’s explore practical examples using Python:
1. Word Count Example:
This classic example demonstrates how MapReduce can efficiently count the occurrences of words in a large text file.
Python Code:
import collections
def mapper(line):
"""Splits the line into words and emits each word as a key-value pair."""
for word in line.split():
yield (word, 1)
def reducer(key, values):
"""Sums the values for each key."""
return (key, sum(values))
def word_count(filename):
"""Performs word count on the given file."""
with open(filename, 'r') as file:
words = []
for line in file:
for word, count in mapper(line):
words.append((word, count))
word_counts = collections.defaultdict(list)
for word, count in words:
word_counts[word].append(count)
result = []
for word, counts in word_counts.items():
result.append(reducer(word, counts))
return result
# Example usage
filename = 'sample_text.txt'
word_counts = word_count(filename)
for word, count in word_counts:
print(f"Word: word, Count: count")Explanation:
-
Mapper: The
mapperfunction splits each line into individual words and emits each word as a key-value pair, where the word is the key and 1 is the count. -
Reducer: The
reducerfunction receives the key (word) and a list of values (counts) for that word. It sums the counts to get the total occurrence of the word. -
Word Count Function: The
word_countfunction reads the input file, applies the mapper and reducer functions, and finally returns a list of (word, count) pairs.
2. Finding Average Temperature Example:
This example demonstrates how MapReduce can calculate the average temperature across multiple cities.
Python Code:
def mapper(line):
"""Parses the line and emits city and temperature as key-value pairs."""
city, temperature = line.split(',')
yield (city, float(temperature))
def reducer(key, values):
"""Calculates the average temperature for the given city."""
total_temp = sum(values)
avg_temp = total_temp / len(values)
return (key, avg_temp)
def average_temperature(filename):
"""Calculates average temperature for each city in the file."""
with open(filename, 'r') as file:
cities = []
for line in file:
for city, temp in mapper(line):
cities.append((city, temp))
city_temps = collections.defaultdict(list)
for city, temp in cities:
city_temps[city].append(temp)
result = []
for city, temps in city_temps.items():
result.append(reducer(city, temps))
return result
# Example usage
filename = 'temperature_data.csv'
avg_temps = average_temperature(filename)
for city, temp in avg_temps:
print(f"City: city, Average Temperature: temp")Explanation:
-
Mapper: The
mapperfunction parses each line, extracts the city and temperature, and emits them as a key-value pair. -
Reducer: The
reducerfunction receives the city name (key) and a list of temperatures (values). It calculates the average temperature for the city. -
Average Temperature Function: The
average_temperaturefunction reads the input file, applies the mapper and reducer functions, and returns a list of (city, average temperature) pairs.
3. Grouping Customers by Purchase Amount Example:
This example showcases how MapReduce can group customers based on their purchase amounts.
Python Code:
def mapper(line):
"""Parses the line and emits customer ID and purchase amount as key-value pairs."""
customer_id, purchase_amount = line.split(',')
yield (customer_id, float(purchase_amount))
def reducer(key, values):
"""Groups customers based on purchase amount ranges."""
if sum(values) < 100:
return (key, 'Low Spender')
elif sum(values) >= 100 and sum(values) < 500:
return (key, 'Medium Spender')
else:
return (key, 'High Spender')
def customer_segmentation(filename):
"""Segments customers based on purchase amounts."""
with open(filename, 'r') as file:
customers = []
for line in file:
for customer_id, amount in mapper(line):
customers.append((customer_id, amount))
customer_groups = collections.defaultdict(list)
for customer_id, amount in customers:
customer_groups[customer_id].append(amount)
result = []
for customer_id, amounts in customer_groups.items():
result.append(reducer(customer_id, amounts))
return result
# Example usage
filename = 'purchase_data.csv'
customer_segments = customer_segmentation(filename)
for customer_id, segment in customer_segments:
print(f"Customer ID: customer_id, Segment: segment")Explanation:
-
Mapper: The
mapperfunction parses each line, extracts the customer ID and purchase amount, and emits them as a key-value pair. -
Reducer: The
reducerfunction receives the customer ID (key) and a list of purchase amounts (values). It sums the amounts and categorizes the customer into different spending segments (Low, Medium, High). -
Customer Segmentation Function: The
customer_segmentationfunction reads the input file, applies the mapper and reducer functions, and returns a list of (customer ID, segment) pairs.
Advantages of MapReduce in Python
The MapReduce model, particularly when implemented in Python, offers several compelling advantages:
- Scalability: MapReduce excels in handling massive datasets. The ability to distribute processing across multiple nodes (cluster computing) allows for efficient parallel execution, making it suitable for big data applications.
- Parallelism: MapReduce inherently supports parallel processing, enabling the execution of map and reduce functions concurrently on different data partitions. This significantly reduces the overall execution time, especially for large datasets.
- Fault Tolerance: The distributed nature of MapReduce provides resilience against node failures. If a node fails during processing, the framework can seamlessly re-distribute the tasks to other available nodes, ensuring data integrity and task completion.
- Simplicity: The MapReduce model promotes a simple and intuitive programming paradigm. Developers can focus on defining the map and reduce functions, leaving the complex parallelization and distribution details to the framework.
- Flexibility: MapReduce can be used for a wide range of data processing tasks, including word counting, aggregation, filtering, sorting, and more. Its adaptability makes it a valuable tool for various data analysis scenarios.
FAQs about MapReduce in Python
Q: How does MapReduce handle data distribution and communication?
A: MapReduce frameworks handle data distribution and communication seamlessly. They partition the input data into smaller chunks and distribute them to different nodes for processing. The map and reduce functions are executed on these chunks in parallel. Communication between nodes occurs through a distributed file system, where intermediate results are stored and accessed by other nodes.
Q: What are some popular MapReduce frameworks in Python?
A: Popular MapReduce frameworks in Python include:
- Hadoop: A widely used open-source framework for distributed storage and processing of large datasets.
- Spark: A fast and general-purpose cluster computing framework that supports MapReduce as well as other programming models.
- Dask: A flexible library for parallel computing in Python, providing a MapReduce-like interface for distributed data processing.
Q: What are the limitations of MapReduce?
A: While MapReduce is powerful, it has certain limitations:
- Data Locality: MapReduce may not always optimize data locality, meaning that data might be processed on nodes far from where it is stored, leading to increased network overhead.
- Iteration Complexity: Iterative tasks, such as machine learning algorithms, can be challenging to implement efficiently with MapReduce.
- Limited Data Structures: MapReduce primarily works with key-value pairs, which might not be suitable for all data structures and operations.
Tips for Using MapReduce in Python
- Optimize Data Partitioning: Choose appropriate data partitioning strategies to ensure balanced workloads and minimize communication overhead.
- Consider Data Locality: When possible, try to process data on nodes where it is stored to reduce network transfer time.
- Use Efficient Data Structures: Select data structures that are compatible with the MapReduce paradigm and optimize performance.
- Test and Profile: Thoroughly test your MapReduce programs and use profiling tools to identify performance bottlenecks and optimize code execution.
Conclusion
MapReduce in Python provides a powerful and versatile framework for processing large datasets. Its inherent parallelism, scalability, and fault tolerance make it an ideal choice for big data applications. By understanding the core concepts of MapReduce, exploring practical examples, and leveraging its advantages, developers can effectively harness its capabilities for efficient and robust data analysis. While MapReduce has its limitations, its simplicity, flexibility, and scalability continue to make it a valuable tool in the data processing landscape.

![2. MapReduce with Python - Hadoop with Python [Book]](https://www.oreilly.com/api/v2/epubs/9781492048435/files/assets/hdpy_0201.png)

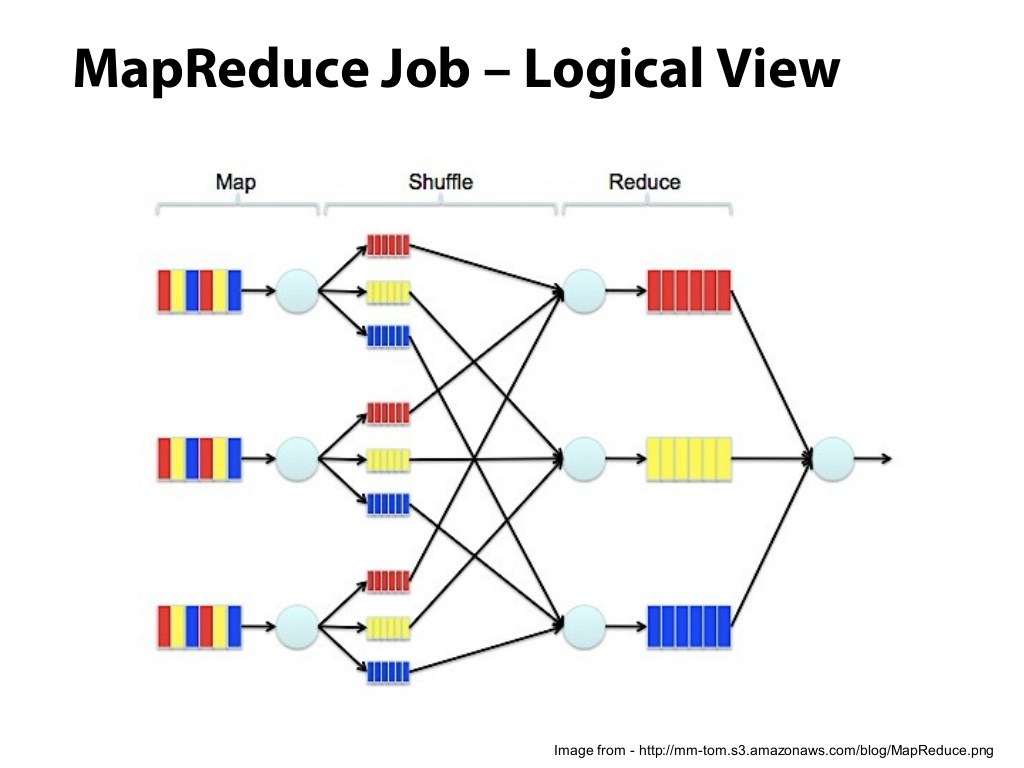

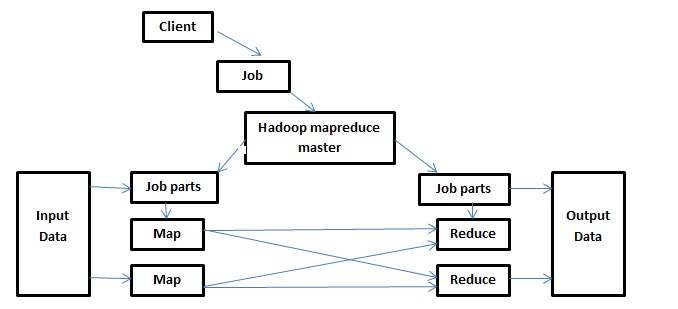

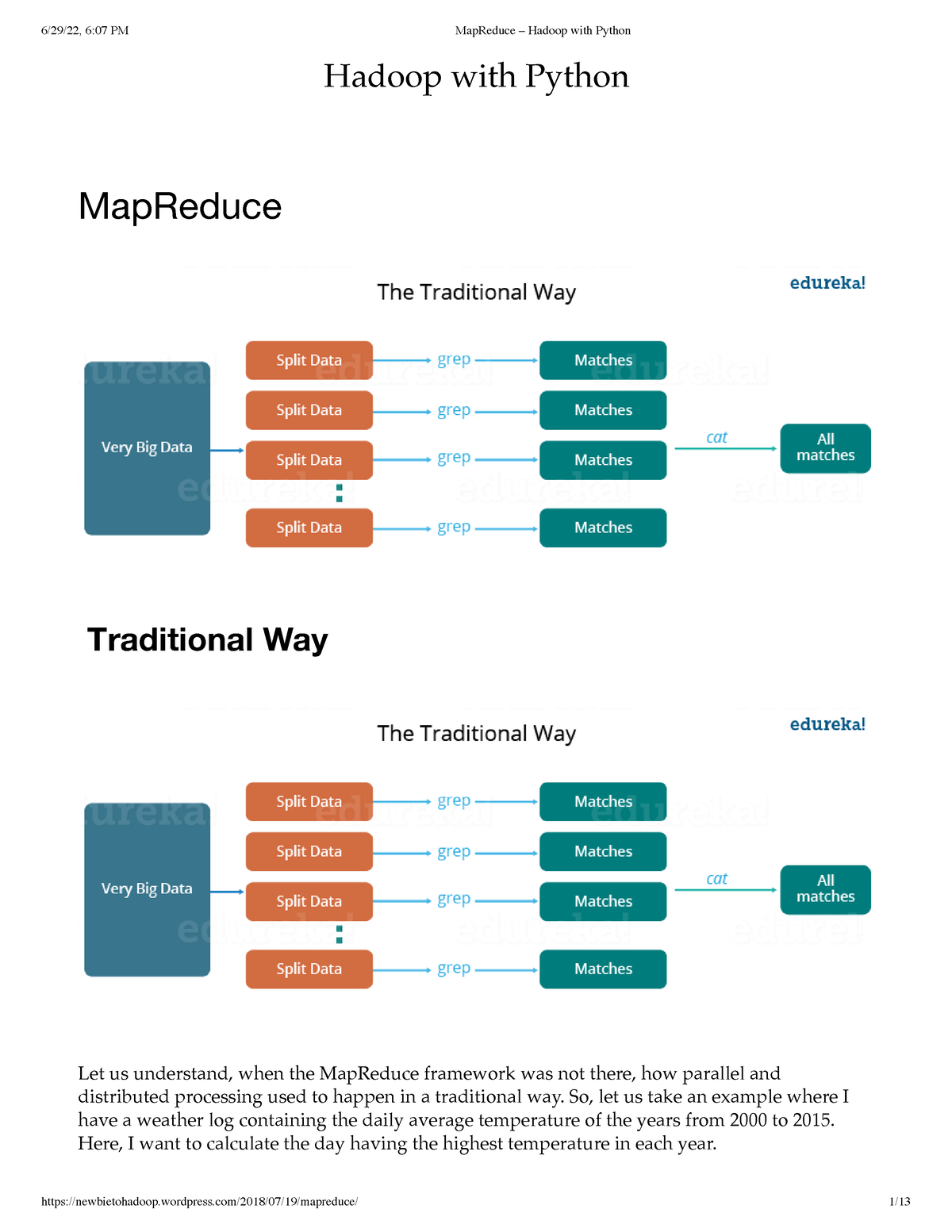
Closure
Thus, we hope this article has provided valuable insights into Unveiling the Power of MapReduce in Python: A Comprehensive Guide. We hope you find this article informative and beneficial. See you in our next article!