Unveiling the Power of Dimensionality Reduction: A Deep Dive into the UMAP Python Library
Related Articles: Unveiling the Power of Dimensionality Reduction: A Deep Dive into the UMAP Python Library
Introduction
With great pleasure, we will explore the intriguing topic related to Unveiling the Power of Dimensionality Reduction: A Deep Dive into the UMAP Python Library. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Unveiling the Power of Dimensionality Reduction: A Deep Dive into the UMAP Python Library

In the realm of data analysis, navigating high-dimensional datasets presents a formidable challenge. The curse of dimensionality, characterized by the exponential growth of data complexity with increasing dimensions, hampers the effectiveness of traditional visualization and machine learning techniques. To combat this, dimensionality reduction techniques have emerged as indispensable tools, offering a pathway to distill complex datasets into lower-dimensional representations that retain essential information.
Among the prominent dimensionality reduction methods, Uniform Manifold Approximation and Projection (UMAP) stands out as a powerful and versatile algorithm. This article delves into the UMAP Python library, exploring its core principles, implementation, and diverse applications. We will shed light on its advantages, delve into its capabilities, and provide practical insights for effectively leveraging this library in data analysis tasks.
Understanding the Essence of UMAP
UMAP is a non-linear dimensionality reduction technique rooted in the concept of topological data analysis. It aims to preserve the global structure and local neighborhood relationships within the original high-dimensional data. This approach distinguishes UMAP from other dimensionality reduction methods, such as Principal Component Analysis (PCA), which primarily focuses on preserving variance.
The Core Principles of UMAP
At its heart, UMAP operates on the principle of constructing a low-dimensional representation of the data that closely reflects the underlying manifold structure of the high-dimensional space. This manifold is a geometric object that captures the intrinsic relationships between data points. UMAP achieves this through the following steps:
-
Building a Neighborhood Graph: UMAP constructs a graph representing the local neighborhood relationships between data points. This graph captures the proximity of data points in the high-dimensional space.
-
Finding a Low-Dimensional Embedding: UMAP seeks a low-dimensional embedding of the data that minimizes the distance between connected points in the graph, thereby preserving the local neighborhood structure.
-
Optimizing for Global Structure: UMAP further optimizes the embedding by considering the global structure of the data, ensuring that distant points in the high-dimensional space are also well-represented in the low-dimensional space.
The UMAP Python Library: A Powerful Tool for Data Analysis
The UMAP Python library provides a user-friendly interface for implementing the UMAP algorithm. It offers a comprehensive set of functionalities, allowing users to customize the algorithm’s parameters to suit specific data analysis needs.
Key Features of the UMAP Python Library:
-
Ease of Use: The library provides a simple and intuitive API, making it accessible to users with varying levels of programming experience.
-
Flexibility: UMAP offers a wide range of customizable parameters, enabling users to fine-tune the algorithm’s behavior based on the characteristics of their data.
-
Visualization Capabilities: The library includes visualization tools that facilitate the exploration and interpretation of the reduced data.
-
Integration with Other Libraries: UMAP integrates seamlessly with other popular Python libraries, such as scikit-learn, for seamless data processing and analysis workflows.
Applications of UMAP in Data Analysis
The versatility of UMAP makes it applicable across various data analysis domains, including:
-
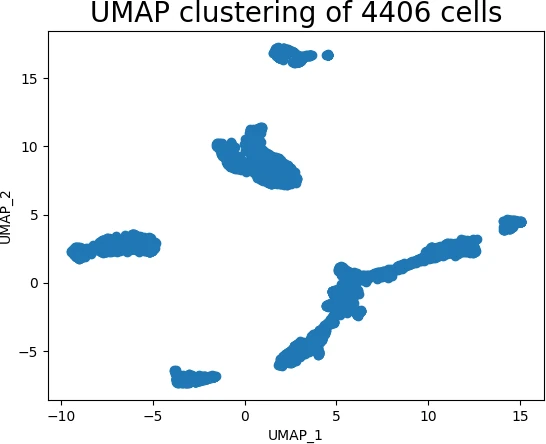
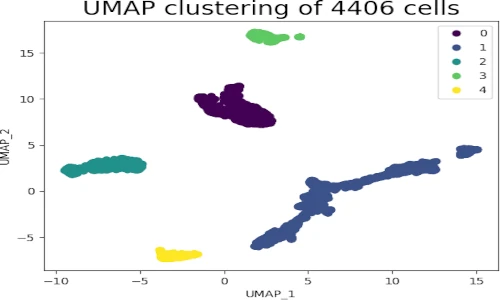
Data Visualization: UMAP enables the visualization of high-dimensional datasets in a lower-dimensional space, revealing hidden patterns and relationships that might be obscured in the original space.
-
Machine Learning: UMAP can be used as a preprocessing step for machine learning models, improving their performance by reducing the dimensionality of the input features.
-
Clustering and Anomaly Detection: UMAP can be used to cluster data points based on their proximity in the low-dimensional space, identifying distinct groups and outliers.
-
Bioinformatics: UMAP has found applications in bioinformatics, aiding in the analysis of complex biological data, such as gene expression profiles and protein interactions.
FAQs about UMAP Python
Q: What are the key advantages of UMAP over other dimensionality reduction techniques?
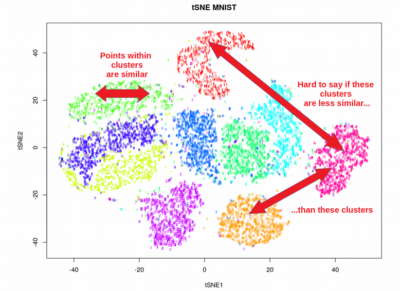
A: UMAP excels in preserving both local and global structure, making it particularly effective for datasets with complex relationships between data points. It also tends to be faster than some other non-linear methods, such as t-SNE.
Q: How can I choose the optimal parameters for UMAP?
A: The choice of parameters depends on the specific characteristics of the data. Experimentation and visualization are crucial. The library offers helpful documentation and tutorials to guide parameter selection.
Q: Can UMAP handle datasets with missing values?
A: Yes, UMAP can handle missing values. The library provides options for handling missing data, such as imputation or ignoring missing values.
Q: How can I interpret the results of UMAP?
A: Visualization tools, such as scatter plots and interactive plots, can be used to interpret the low-dimensional embedding. Examining the proximity of data points in the reduced space can reveal insights into their relationships in the original high-dimensional space.
Tips for Using UMAP Python
-
Start with Default Parameters: Begin by using the default parameters of the UMAP algorithm to get a baseline understanding of the reduced data.
-
Experiment with Parameters: Explore different values for parameters such as
n_neighbors,min_dist, andn_componentsto fine-tune the algorithm’s behavior. -
Visualize the Results: Use visualization tools to explore the reduced data and identify patterns, clusters, and outliers.
-
Consider Data Preprocessing: Preprocessing steps, such as scaling or normalization, can improve the performance of UMAP by addressing potential issues related to data scaling.
Conclusion
The UMAP Python library empowers data scientists and analysts to effectively tackle the challenges of high-dimensional datasets. Its ability to preserve both local and global structure, coupled with its user-friendly interface and integration with other libraries, makes it a valuable tool for data visualization, machine learning, and other data analysis tasks. By embracing the power of UMAP, researchers and practitioners can gain deeper insights into their data and unlock new avenues for exploration and discovery.




Closure
Thus, we hope this article has provided valuable insights into Unveiling the Power of Dimensionality Reduction: A Deep Dive into the UMAP Python Library. We thank you for taking the time to read this article. See you in our next article!