Unlocking the Power of High-Dimensional Data: A Comprehensive Guide to UMAP in Python
Related Articles: Unlocking the Power of High-Dimensional Data: A Comprehensive Guide to UMAP in Python
Introduction
With great pleasure, we will explore the intriguing topic related to Unlocking the Power of High-Dimensional Data: A Comprehensive Guide to UMAP in Python. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
Unlocking the Power of High-Dimensional Data: A Comprehensive Guide to UMAP in Python
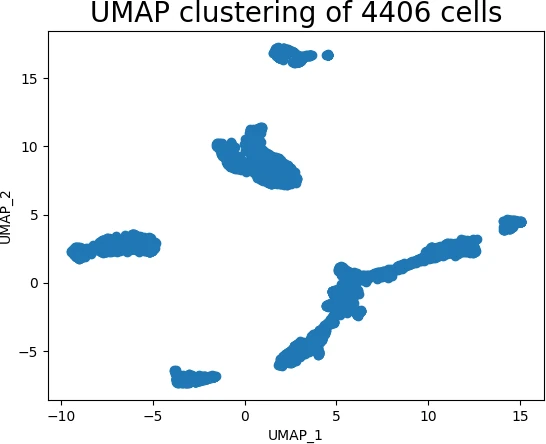
The ever-increasing volume and complexity of data in various fields, from scientific research to business analytics, pose a significant challenge: understanding and visualizing high-dimensional datasets. While human perception is limited to three dimensions, real-world data often involves hundreds or even thousands of features, making traditional visualization techniques ineffective. Here, dimensionality reduction techniques come into play, offering a powerful solution to simplify complex data and extract meaningful insights.
Among these techniques, Uniform Manifold Approximation and Projection (UMAP) stands out as a robust and versatile algorithm, particularly well-suited for handling large, high-dimensional datasets. This article delves into the world of UMAP in Python, providing a comprehensive overview of its capabilities, implementation, and applications.
Understanding UMAP: A Bridge Between High and Low Dimensions
UMAP’s core strength lies in its ability to preserve the local neighborhood structure of data points during dimensionality reduction. This is achieved by constructing a low-dimensional representation that closely resembles the original high-dimensional space, allowing for insightful visualization and analysis.
Key Concepts Behind UMAP:
- Manifold Learning: UMAP operates on the principle that high-dimensional data often lies on a lower-dimensional manifold, a geometric structure embedded in the higher-dimensional space.
- Neighborhood Preservation: The algorithm prioritizes preserving the local relationships between data points, ensuring that nearby points in the high-dimensional space remain close in the reduced representation.
- Global Structure: While focusing on local neighborhoods, UMAP also considers global relationships, maintaining the overall structure of the dataset in the lower-dimensional space.
- Non-linearity: UMAP can effectively handle non-linear relationships between data points, making it suitable for complex datasets with intricate structures.
Implementation in Python: A Practical Guide
UMAP’s implementation in Python is made seamless through the umap library, which provides a user-friendly interface for applying the algorithm to various datasets.
Steps to Implementing UMAP in Python:
-
Installation: Begin by installing the
umaplibrary using pip:pip install umap-learn -
Import Libraries: Import the necessary libraries, including
umapand any other libraries required for data loading and preprocessing. -
Data Preparation: Load your dataset and ensure it is properly formatted for UMAP. This may involve preprocessing steps like scaling, normalization, or feature selection.
-
UMAP Initialization: Create a
UMAPobject and specify the desired parameters. Key parameters include:-
n_neighbors: Controls the local neighborhood size, influencing the smoothness of the resulting embedding. -
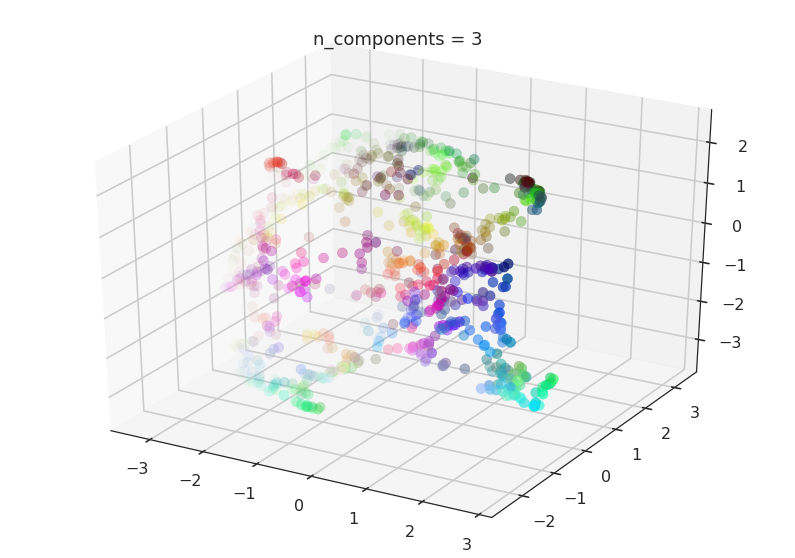
n_components: Specifies the target number of dimensions for the reduced representation. -
metric: Defines the distance metric used for calculating neighborhood distances. -
min_dist: Influences the crowding of points in the reduced space.
-
-
Fitting and Transforming: Fit the UMAP model to your data and transform it to the lower-dimensional space.
-
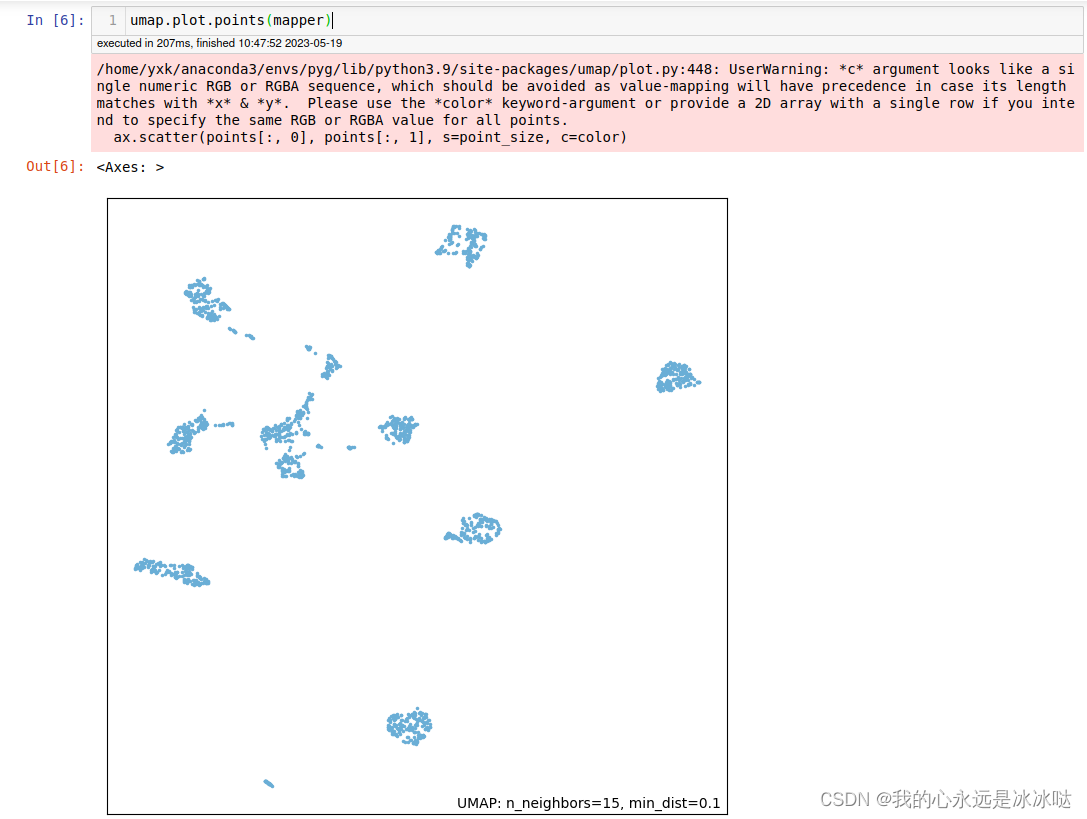
Visualization: Use a suitable visualization library, such as Matplotlib or Seaborn, to plot the reduced data and explore its structure.
Example Code:
import umap
import pandas as pd
import matplotlib.pyplot as plt
# Load data
data = pd.read_csv('your_data.csv')
# Create UMAP object
reducer = umap.UMAP(n_neighbors=15, n_components=2)
# Fit and transform data
embedding = reducer.fit_transform(data)
# Plot the embedding
plt.scatter(embedding[:, 0], embedding[:, 1])
plt.show()Benefits and Applications of UMAP:
UMAP’s strengths in preserving local and global data structures make it a powerful tool for various applications, including:
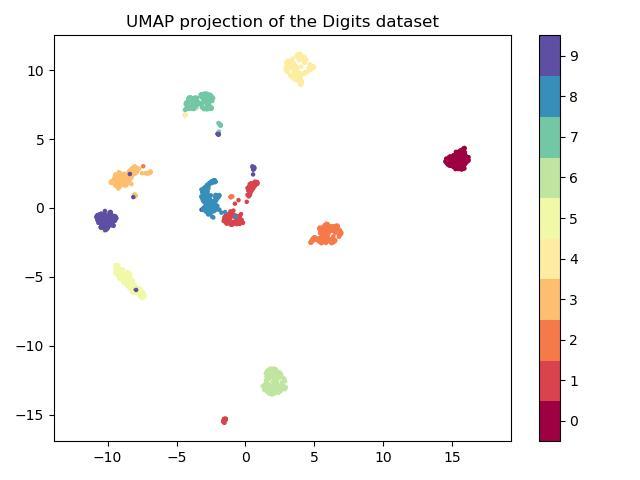
- Data Visualization: UMAP provides a clear and insightful way to visualize high-dimensional data, allowing for the identification of clusters, outliers, and relationships between data points.
- Clustering and Classification: UMAP’s ability to preserve local relationships can enhance the performance of clustering algorithms, leading to more accurate and meaningful cluster assignments.
- Feature Engineering: UMAP can be used to generate low-dimensional features from high-dimensional data, which can be used as input for other machine learning models.
- Anomaly Detection: UMAP can help identify outliers in high-dimensional data by revealing points that are distant from the main data manifold.
- Data Exploration: UMAP facilitates the exploration and understanding of complex datasets, allowing researchers to gain deeper insights into the underlying structure and relationships within the data.
UMAP in Action: Real-World Examples
UMAP’s versatility has led to its widespread adoption in various domains:
- Bioinformatics: UMAP has been used to analyze gene expression data, identifying patterns and relationships between different cell types.
- Image Analysis: UMAP helps visualize and analyze high-dimensional image data, enabling the identification of distinct image categories or patterns.
- Natural Language Processing: UMAP has been applied to reduce the dimensionality of text data, allowing for better visualization of document relationships and the identification of thematic clusters.
- Machine Learning: UMAP serves as a powerful preprocessing technique, enhancing the performance of various machine learning algorithms by providing a more informative and concise representation of the data.
Frequently Asked Questions about UMAP:
-
Q: What are the key advantages of UMAP over other dimensionality reduction techniques like Principal Component Analysis (PCA)?
- A: UMAP excels in handling non-linear relationships in data, unlike PCA which assumes linearity. It also prioritizes preserving local neighborhood structures, making it more effective for visualizing complex datasets.
-
Q: How do I choose the optimal parameters for UMAP?
- A: Experimentation is key! Start with default parameters and then adjust based on your data and specific needs. Visualizing the results with different parameter settings can help identify the best configuration.
-
Q: What are the limitations of UMAP?
- A: UMAP can be computationally intensive for very large datasets, and its performance can be sensitive to the choice of parameters.
-
Q: Can UMAP be used for both supervised and unsupervised learning?
- A: While primarily an unsupervised technique, UMAP can be integrated into supervised learning tasks, particularly for feature engineering or visualization of labeled data.
Tips for Using UMAP Effectively:
- Preprocess Data: Ensure your data is properly scaled and normalized before applying UMAP.
- Experiment with Parameters: Explore different parameter settings to find the best configuration for your specific dataset.
- Visualize the Results: Use visualization tools to understand the structure of the reduced data and identify potential insights.
- Consider Alternative Techniques: Explore other dimensionality reduction techniques, like t-SNE, to compare results and identify the most suitable approach for your problem.
Conclusion:
UMAP has emerged as a powerful and versatile tool for dimensionality reduction, offering a unique combination of local neighborhood preservation and global structure maintenance. Its ability to handle non-linear relationships and reveal hidden patterns in high-dimensional data makes it a valuable asset for data scientists, researchers, and analysts across various domains. By leveraging the capabilities of UMAP in Python, researchers can unlock the hidden potential of complex data, gain deeper insights, and make more informed decisions. As the volume and complexity of data continue to grow, UMAP’s role in simplifying and understanding this data will only become more crucial in the years to come.





Closure
Thus, we hope this article has provided valuable insights into Unlocking the Power of High-Dimensional Data: A Comprehensive Guide to UMAP in Python. We appreciate your attention to our article. See you in our next article!