Demystifying MapReduce with Python: A Practical Guide
Related Articles: Demystifying MapReduce with Python: A Practical Guide
Introduction
With great pleasure, we will explore the intriguing topic related to Demystifying MapReduce with Python: A Practical Guide. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Demystifying MapReduce with Python: A Practical Guide
- 2 Introduction
- 3 Demystifying MapReduce with Python: A Practical Guide
- 3.1 Understanding the MapReduce Paradigm
- 3.2 Illustrative Example: Word Count
- 3.3 Advantages of MapReduce
- 3.4 Python Libraries for MapReduce
- 3.5 FAQs about MapReduce with Python
- 3.6 Tips for Implementing MapReduce in Python
- 3.7 Conclusion
- 4 Closure
Demystifying MapReduce with Python: A Practical Guide
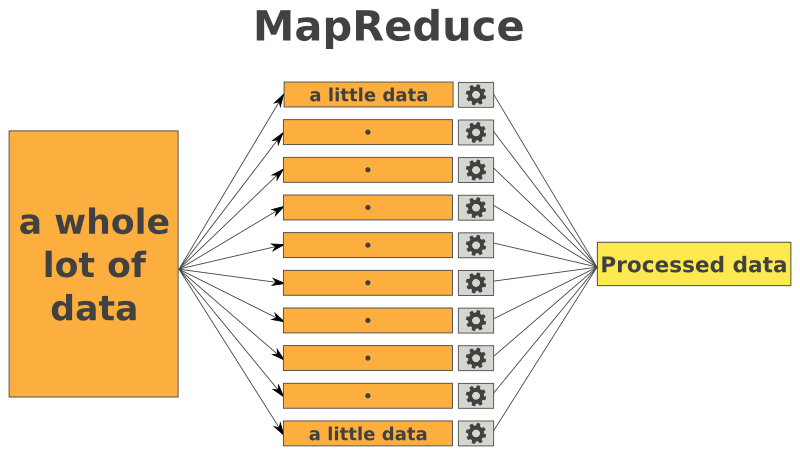
The concept of MapReduce, a paradigm for processing large datasets, has gained significant traction in the realm of data science and engineering. Its core principle lies in dividing a complex problem into smaller, manageable tasks, enabling efficient parallel processing. This approach is particularly valuable when dealing with massive datasets that might overwhelm traditional processing methods.
Python, with its rich libraries and intuitive syntax, provides a powerful platform for implementing MapReduce algorithms. This article delves into the fundamental principles of MapReduce and illustrates its practical application using Python examples.
Understanding the MapReduce Paradigm
At its core, MapReduce operates in two distinct phases:
1. Map Phase:
- Input: The initial dataset is divided into smaller chunks, each of which is processed independently.
- Function: A user-defined "map" function operates on each chunk, transforming the data into key-value pairs.
- Output: The map phase produces a set of key-value pairs, which are then passed to the reduce phase.
2. Reduce Phase:
- Input: The key-value pairs generated by the map phase are grouped by their keys.
- Function: A user-defined "reduce" function iterates over the values associated with each key, performing an aggregation operation.
- Output: The reduce phase generates a final output, which represents the result of the MapReduce operation.
Illustrative Example: Word Count
A classic example of MapReduce is the word count problem, where the goal is to count the occurrences of each word in a large text document. Let’s break down this process using Python:
1. Map Phase:
def map_word_count(line):
"""
Map function for word counting.
Args:
line: A line of text from the input document.
Returns:
A list of key-value pairs, where the key is the word and the value is 1.
"""
words = line.split()
for word in words:
yield (word, 1)This map function takes a line of text as input, splits it into individual words, and generates a key-value pair for each word. The key is the word itself, and the value is 1, representing a single occurrence.
2. Reduce Phase:
def reduce_word_count(key, values):
"""
Reduce function for word counting.
Args:
key: A word from the input data.
values: A list of values (1s) associated with the word.
Returns:
A key-value pair, where the key is the word and the value is the total count.
"""
return (key, sum(values))The reduce function takes a word (key) and a list of values (occurrences) as input. It then sums the values to determine the total count of the word and returns a key-value pair representing the word and its count.
3. Execution:
from functools import reduce
# Sample text data
text = "This is a sample text. This text has sample words."
# Map phase
mapped_data = []
for line in text.split("."):
mapped_data.extend(map_word_count(line))
# Reduce phase
reduced_data =
for key, value in mapped_data:
if key in reduced_data:
reduced_data[key] += value
else:
reduced_data[key] = value
# Print results
for key, value in reduced_data.items():
print(f"key: value")This code demonstrates the MapReduce process for word counting. The map function processes each line of text, generating key-value pairs. The reduce function then aggregates the values associated with each word, resulting in a final count for each word.
Advantages of MapReduce
- Scalability: MapReduce is inherently designed for handling large datasets. It can be easily scaled by distributing the processing across multiple machines.
- Parallelism: The map and reduce phases can be executed concurrently, significantly accelerating processing time.
- Fault Tolerance: If one machine fails during processing, the framework can automatically redistribute the workload to other available machines, ensuring continued operation.
- Simplicity: The MapReduce paradigm simplifies complex data processing tasks by breaking them down into smaller, manageable units.
Python Libraries for MapReduce
While Python provides the core functionality for implementing MapReduce, several libraries offer more convenient abstractions and support for distributed execution:
- Dask: Dask is a flexible library for parallel computing in Python. It provides a high-level interface for working with large datasets and supports distributed execution on clusters.
- Spark: Apache Spark is a powerful open-source framework for large-scale data processing. It provides a rich set of libraries for data manipulation, analysis, and machine learning, and supports MapReduce as one of its core processing models.
FAQs about MapReduce with Python
1. What are the limitations of MapReduce?
- Data Shuffle Overhead: The transfer of data between the map and reduce phases can introduce overhead, especially for large datasets.
- Limited Flexibility: MapReduce is primarily suited for batch processing tasks and may not be ideal for real-time applications.
- Data Locality: The distribution of data across multiple machines can impact performance if data is not stored locally.
2. How does MapReduce handle data sorting?
The framework typically uses a distributed sorting algorithm to ensure that data is correctly grouped by key before the reduce phase.
3. What are some common applications of MapReduce?
- Data Analysis: Processing large datasets for insights and trends.
- Machine Learning: Training models on massive datasets.
- Web Search: Indexing and ranking web pages.
- Social Media Analysis: Understanding user behavior and trends.
Tips for Implementing MapReduce in Python
- Optimize Data Partitioning: Choose a suitable partitioning strategy to minimize data transfer overhead.
- Use Efficient Data Structures: Select data structures that are efficient for the specific tasks involved.
- Leverage Distributed Storage: Utilize distributed storage systems like Hadoop Distributed File System (HDFS) for storing and accessing large datasets.
- Consider Library Support: Explore libraries like Dask and Spark for streamlined MapReduce implementation.
Conclusion
MapReduce, with its inherent parallelism and scalability, provides a powerful framework for processing large datasets. Python, with its rich ecosystem of libraries and its intuitive syntax, offers a convenient platform for implementing MapReduce algorithms. By understanding the core concepts of MapReduce and leveraging its benefits, developers can tackle complex data processing challenges efficiently and effectively.
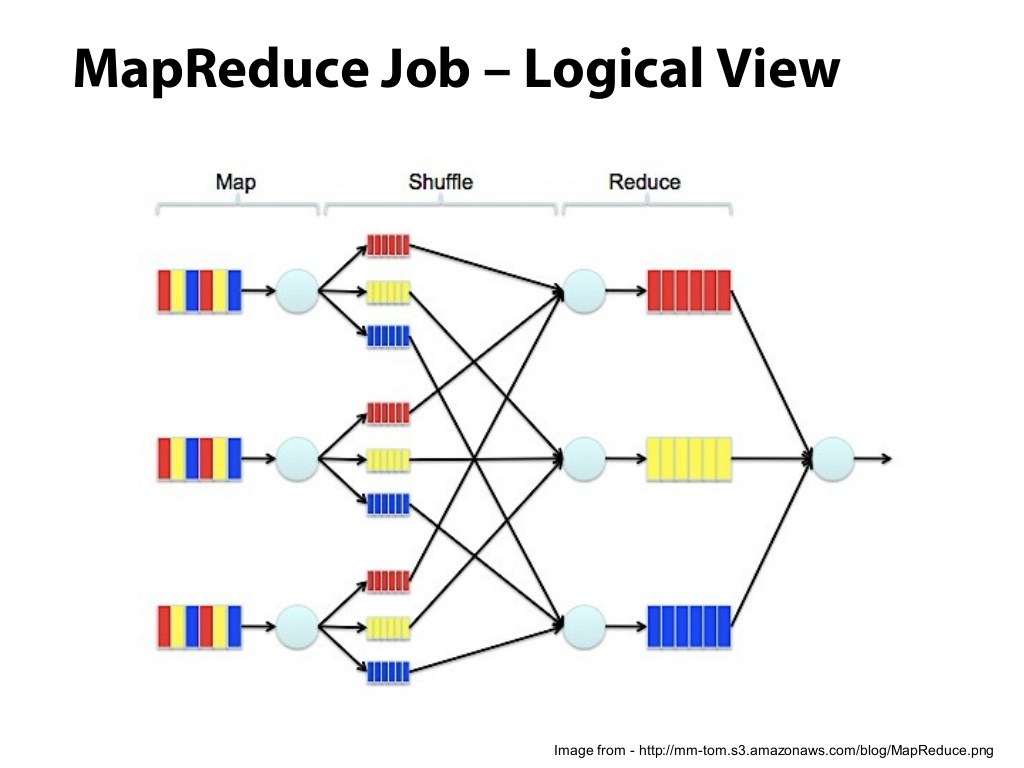



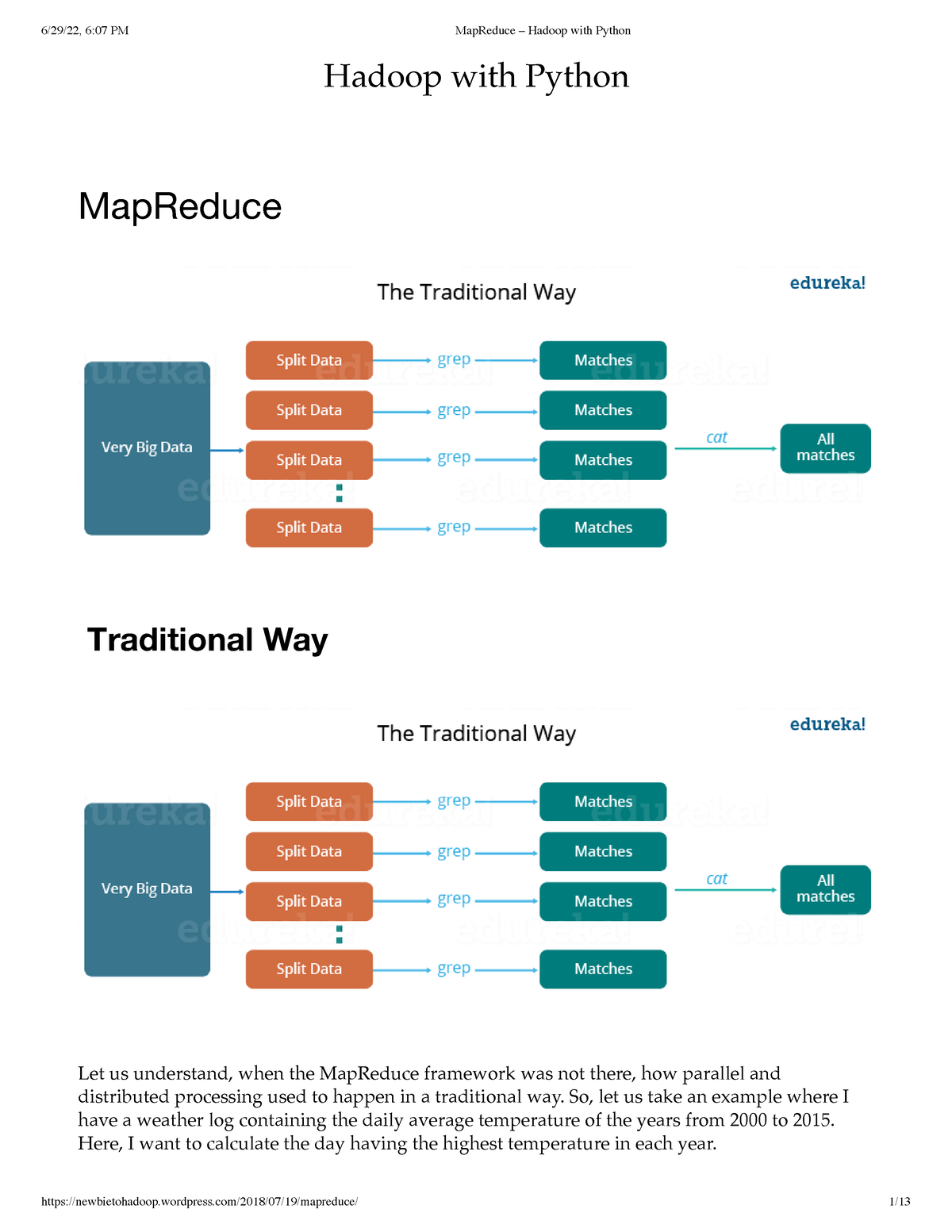


![2. MapReduce with Python - Hadoop with Python [Book]](https://www.oreilly.com/api/v2/epubs/9781492048435/files/assets/hdpy_0201.png)
Closure
Thus, we hope this article has provided valuable insights into Demystifying MapReduce with Python: A Practical Guide. We hope you find this article informative and beneficial. See you in our next article!