A Comprehensive Guide to Map-Reduce Programming in Python
Related Articles: A Comprehensive Guide to Map-Reduce Programming in Python
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to A Comprehensive Guide to Map-Reduce Programming in Python. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: A Comprehensive Guide to Map-Reduce Programming in Python
- 2 Introduction
- 3 A Comprehensive Guide to Map-Reduce Programming in Python
- 3.1 Understanding MapReduce
- 3.2 Python Libraries for MapReduce
- 3.3 Benefits of MapReduce in Python
- 3.4 Applications of MapReduce in Python
- 3.5 Practical Example: Word Count with mrjob
- 3.6 FAQs
- 3.7 Tips for Effective MapReduce Programming in Python
- 3.8 Conclusion
- 4 Closure
A Comprehensive Guide to Map-Reduce Programming in Python
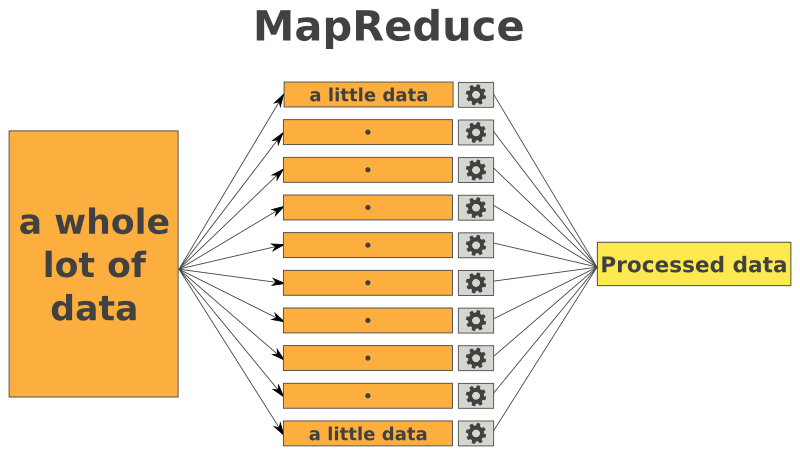
MapReduce, a powerful programming paradigm, has revolutionized data processing by enabling efficient and scalable computation across vast datasets. This paradigm, popularized by Hadoop, is particularly well-suited for handling big data challenges and has found widespread adoption in various domains. Python, with its rich libraries and ease of use, provides an excellent platform for implementing MapReduce applications. This article delves into the intricacies of MapReduce programming in Python, exploring its core concepts, benefits, and practical applications.
Understanding MapReduce
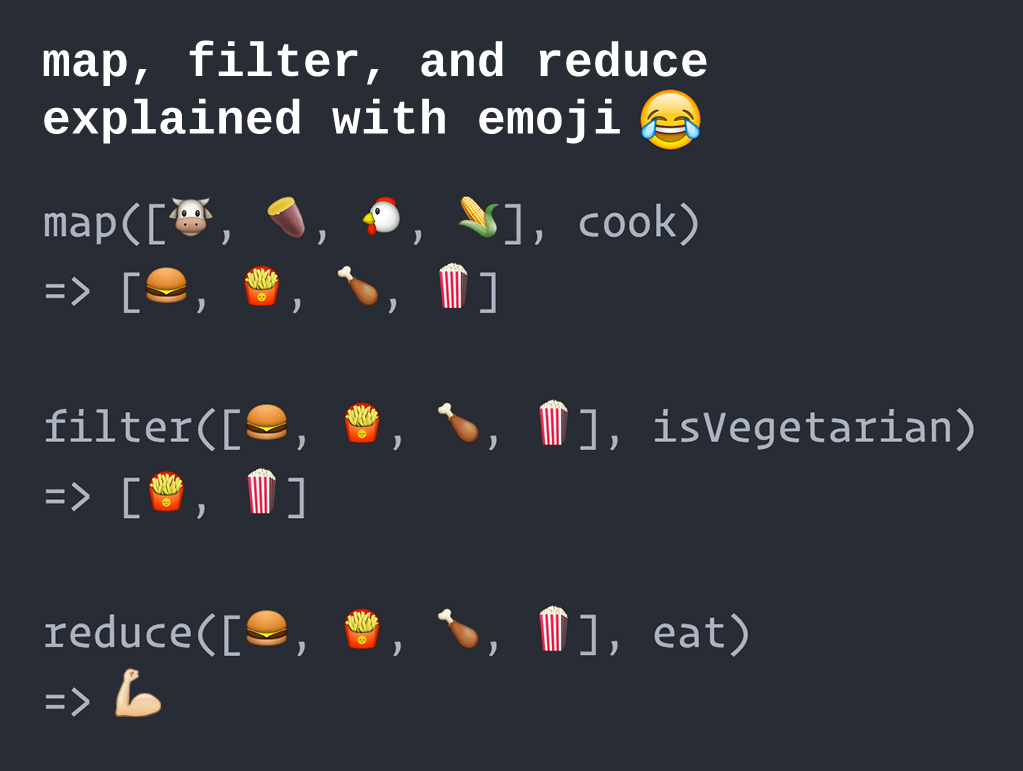
At its core, MapReduce breaks down complex data processing tasks into two fundamental operations: map and reduce.
1. Map: The map phase involves iterating over each input data record and applying a user-defined function, known as the "map function." This function transforms each input record into a key-value pair. The key acts as a grouping mechanism, while the value holds the processed data.
2. Reduce: The reduce phase aggregates the key-value pairs generated by the map phase. It applies another user-defined function, the "reduce function," to each group of values associated with a specific key. This function typically performs operations like summation, averaging, or other aggregations, producing a final output.
Python Libraries for MapReduce
Python offers several libraries that facilitate the implementation of MapReduce algorithms. Some notable ones include:
1. mrjob: This library provides a framework for running MapReduce jobs on various platforms, including Hadoop, Amazon EMR, and local machines. It simplifies the process of defining map and reduce functions and handles the complexities of data distribution and aggregation.
2. Hadoop Streaming: Hadoop Streaming allows users to execute custom scripts written in any language, including Python, as map and reduce tasks within the Hadoop ecosystem. This approach offers flexibility for integrating existing Python code with Hadoop’s distributed processing capabilities.
3. Dask: While not strictly a MapReduce library, Dask offers a powerful framework for parallel and distributed computing in Python. It allows users to define computations on large datasets and execute them efficiently across multiple cores or machines, effectively mimicking the MapReduce paradigm.
Benefits of MapReduce in Python
The adoption of MapReduce in Python offers several compelling benefits:
1. Scalability: MapReduce inherently facilitates parallel processing, enabling the handling of massive datasets by distributing the workload across multiple nodes. This scalability is crucial for modern data-intensive applications.
2. Simplicity: The map and reduce paradigm simplifies complex data processing tasks into manageable, modular units. This modularity enhances code readability, maintainability, and reusability.
3. Fault Tolerance: MapReduce frameworks are designed to be resilient to failures. If a node fails during processing, other nodes can take over, ensuring the completion of the task.
4. Flexibility: Python’s versatility and extensive libraries allow for seamless integration with various data sources and processing techniques, making it suitable for a wide range of applications.
Applications of MapReduce in Python
MapReduce finds application in various domains, including:
1. Data Analytics: Analyzing large datasets to extract valuable insights, such as customer behavior patterns, market trends, and financial anomalies.
2. Machine Learning: Training machine learning models on massive datasets, such as image recognition, natural language processing, and recommendation systems.
3. Search Engines: Indexing and retrieving information from vast databases, enabling efficient search functionality.
4. Social Media Analysis: Understanding user behavior, sentiment analysis, and trend identification in social media platforms.
5. Scientific Computing: Processing large datasets generated from simulations, experiments, and scientific observations.
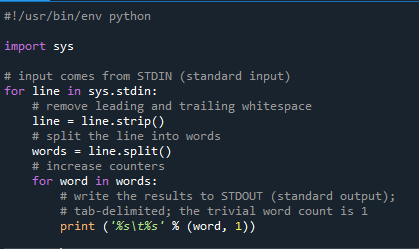
Practical Example: Word Count with mrjob
Let’s illustrate the power of MapReduce in Python with a simple example: counting the occurrences of words in a text file.
from mrjob.job import MRJob
class WordCount(MRJob):
def mapper(self, _, line):
for word in line.split():
yield (word, 1)
def reducer(self, word, counts):
yield (word, sum(counts))
if __name__ == '__main__':
WordCount.run()This code defines a MapReduce job using the mrjob library. The mapper function splits each input line into words and emits a key-value pair for each word, where the key is the word and the value is 1. The reducer function receives all values associated with a particular word and sums them up, producing the final word count.
FAQs
1. What are the limitations of MapReduce?
While powerful, MapReduce has limitations. It might not be the most efficient solution for tasks involving complex data dependencies or requiring real-time processing.
2. How does MapReduce handle data shuffling?
MapReduce frameworks typically employ a shuffling stage between the map and reduce phases. This stage involves sorting and grouping the intermediate key-value pairs, ensuring that all values associated with a specific key are sent to the same reducer.
3. Can I use MapReduce for real-time data processing?
While traditional MapReduce is designed for batch processing, frameworks like Apache Spark offer real-time capabilities, allowing for near-instantaneous data analysis.
4. What are some alternatives to MapReduce?
Alternatives to MapReduce include Apache Spark, Apache Flink, and Apache Storm, each offering unique features and strengths for distributed data processing.
Tips for Effective MapReduce Programming in Python
1. Optimize Map and Reduce Functions: Implement efficient map and reduce functions to minimize processing time and resource consumption.
2. Leverage Data Partitioning: Partition data into smaller chunks to distribute the workload effectively across multiple nodes.
3. Handle Data Skew: Address data skew, where certain keys have significantly more associated values than others, to prevent performance bottlenecks.
4. Monitor and Analyze Job Performance: Utilize monitoring tools to track job progress, identify bottlenecks, and optimize performance.
5. Consider Cloud Platforms: Explore cloud platforms like AWS EMR or Azure HDInsight for scalable and managed MapReduce execution.
Conclusion
MapReduce, implemented in Python, provides a powerful and scalable framework for processing massive datasets. Its simplicity, modularity, and fault tolerance make it a valuable tool for data analytics, machine learning, and other data-intensive applications. By understanding the core concepts, benefits, and practical applications of MapReduce in Python, developers can harness its power to tackle complex data processing challenges efficiently and effectively.






Closure
Thus, we hope this article has provided valuable insights into A Comprehensive Guide to Map-Reduce Programming in Python. We hope you find this article informative and beneficial. See you in our next article!